* Added Feature * Added PSC to CloudSQL module * Added psc to read replica * Changed variables * Updated README * Ran fmt * Removed old variables * Fix README * Fixed blueprints * Fix README * Fixed output * Added more outputs and bug fixes * Changed variable structure * Bug fix * Added PSC example. |
||
|---|---|---|
| .. | ||
| images | ||
| README.md | ||
| backend.tf.sample | ||
| cloudsql.tf | ||
| gce.tf | ||
| main.tf | ||
| outputs.tf | ||
| terraform.tfvars.sample | ||
| variables.tf | ||
README.md
Cloud SQL instance with multi-region read replicas
From startups to enterprises, database disaster recovery planning is critical to provide the continuity of processing. While Cloud SQL does provide high availability within a single region, regional failures or unavailability can occur from cyber attacks to natural disasters. Such incidents or outages lead to a quick domino effect for startups, making it difficult to recover from the loss of revenue and customers, which is especially true for bootstrapped or lean startups. It is critical that your database is regionally resilient and made available promptly in a secondary region. With Cloud SQL for PostgreSQL, you can configure cross-region read replicas for a complete DR failover and fallback process.
This blueprint creates a Cloud SQL instance with multi-region read replicas as described in the Cloud SQL for PostgreSQL disaster recovery article.
The solution is resilient to a regional outage. To get familiar with the procedure needed in the unfortunate case of a disaster recovery, please follow steps described in part two of the aforementioned article.
Use cases:
Configuring the CloudSQL instance for DR can be done in the following steps:
- Create an HA Cloud SQL for PostgreSQL instance.
- Deploy a cross-region read replica on Google Cloud using Cloud SQL for PostgreSQL.
The solution will use:
- VPC with Private Service Access to deploy the instances and VM
- Cloud SQL - Postgre SQL instanced with Private IP
- Goocle Cloud Storage bucket to handle database import/export
- Google Cloud Engine instance to connect to the Posgre SQL instance
- Google Cloud NAT to access internet resources
This is the high level diagram:

If you're migrating from another Cloud Provider, refer to this documentation to see equivalent services and comparisons in Microsoft Azure and Amazon Web Services.
Requirements
This blueprint will deploy all its resources into the project defined by the project_id variable. Please note that we assume this project already exists. However, if you provide the appropriate values to the project_create variable, the project will be created as part of the deployment.
If project_create is left to null, the identity performing the deployment needs the owner role on the project defined by the project_id variable. Otherwise, the identity performing the deployment needs resourcemanager.projectCreator on the resource hierarchy node specified by project_create.parent and billing.user on the billing account specified by project_create.billing_account_id.
Deployment
Step 0: Cloning the repository
Click on the image below, sign in if required and when the prompt appears, click on “confirm”.

This will clone the repository to your cloud shell and a screen like this one will appear:
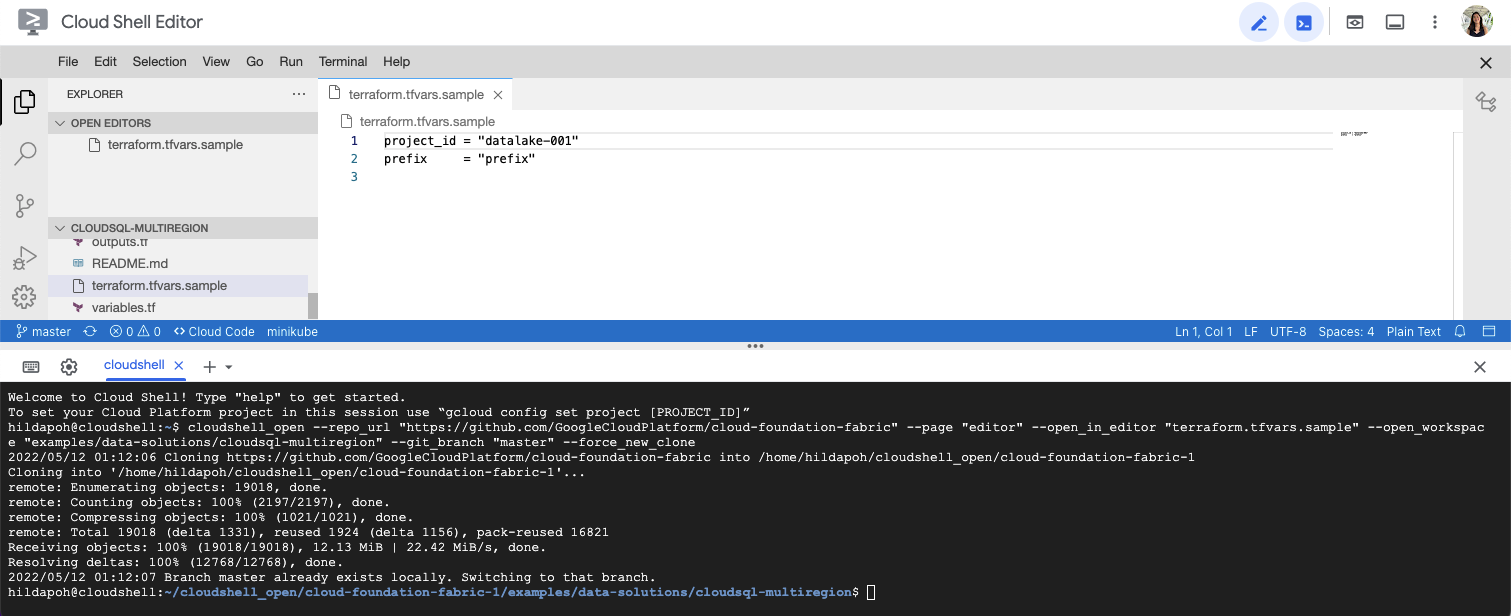
Before you deploy the architecture, make sure you run the following command to move your cloudshell session into your service project: gcloud config set project [SERVICE_PROJECT_ID]
Before we deploy the architecture, you will need the following information:
- The service project ID.
- A unique prefix that you want all the deployed resources to have (for example: cloudsql-multiregion-hpjy). This must be a string with no spaces or tabs.
Once you can see your service project id in the yellow parenthesis, you’re ready to start.
Step 1: Deploy resources
Once you have the required information, head back to the cloud shell editor. Make sure you’re in the following directory: cloudshell_open/cloud-foundation-fabric/blueprints/data-solutions/cloudsql-multiregion/
Configure the Terraform variables in your terraform.tfvars file. You need to specify at least the project_id and prefix variables. See terraform.tfvars.sample as starting point.
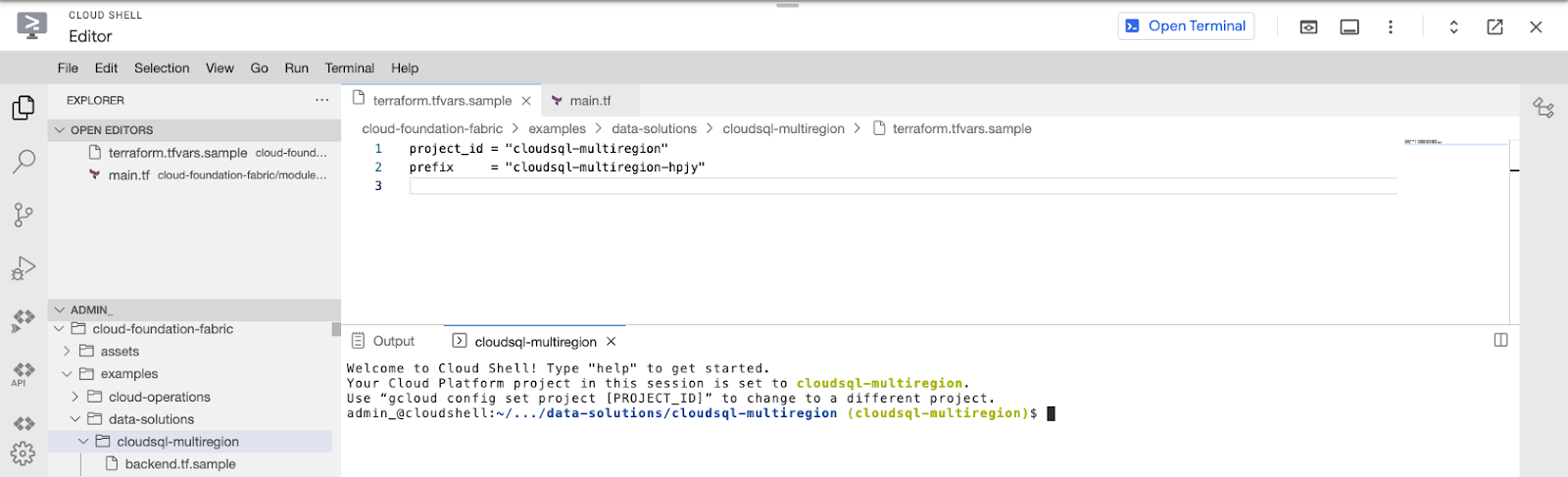
Run Terraform init:
terraform init
terraform apply
The resource creation will take a few minutes, at the end this is the output you should expect for successful completion along with a list of the created resources:
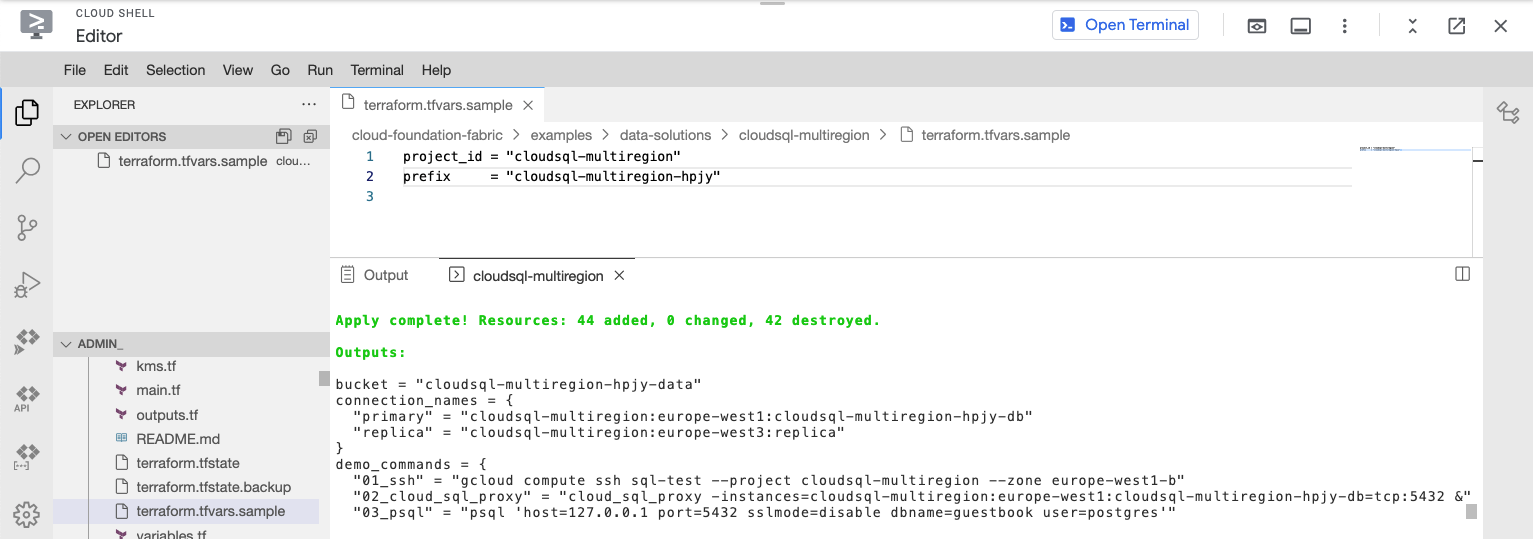
Move to real use case consideration
This implementation is intentionally minimal and easy to read. A real world use case should consider:
- Using a Shared VPC
- Using VPC-SC to mitigate data exfiltration
Shared VPC
The example supports the configuration of a Shared VPC as an input variable.
To deploy the solution on a Shared VPC, you have to configure the network_config variable:
network_config = {
host_project = "PROJECT_ID"
network_self_link = "https://www.googleapis.com/compute/v1/projects/PROJECT_ID/global/networks/VPC_NAME"
subnet_self_link = "https://www.googleapis.com/compute/v1/projects/PROJECT_ID/regions/$REGION/subnetworks/SUBNET_NAME"
cloudsql_psa_range = "10.60.0.0/24"
}
# tftest skip
To run this example, the Shared VPC project needs to have:
- A Private Service Connect with a range of
/24(example:10.60.0.0/24) to deploy the Cloud SQL instance. - Internet access configured (for example Cloud NAT) to let the Test VM download packages.
In order to run the example and deploy Cloud SQL on a shared VPC the identity running Terraform must have the following IAM role on the Shared VPC Host project.
- Compute Network Admin (roles/compute.networkAdmin)
- Compute Shared VPC Admin (roles/compute.xpnAdmin)
Test your environment
We assume all those steps are run using a user listed on data_eng_principals. You can authenticate as the user using the following command:
gcloud init
gcloud auth application-default login
Below you can find commands to connect to the VM instance and Cloud SQL instance.
$ gcloud compute ssh sql-test --project PROJECT_ID --zone ZONE
sql-test:~$ cloud_sql_proxy -instances=CLOUDSQL_INSTANCE=tcp:5432
sql-test:~$ psql 'host=127.0.0.1 port=5432 sslmode=disable dbname=DATABASE user=USER'
You can find computed commands on the Terraform demo_commands output.
How to recover your initial deployment by using a fallback
To implement a fallback to your original region (R1) after it becomes available, you can follow the same process that is described in the above section. The process is summarized here.
Clean up your environment
The easiest way to remove all the deployed resources is to run the following command in Cloud Shell:
terraform destroy
The above command will delete the associated resources so there will be no billable charges made afterwards.
Variables
| name | description | type | required | default |
|---|---|---|---|---|
| postgres_user_password | postgres user password. |
string |
✓ | |
| prefix | Prefix used for resource names. | string |
✓ | |
| project_id | Project id, references existing project if project_create is null. |
string |
✓ | |
| data_eng_principal | Group or user in IAM format (group:foo@example.com) with permissions to access resources and impersonate service accounts. |
string |
null |
|
| deletion_protection | Prevent Terraform from destroying data storage resources (storage buckets, GKE clusters, CloudSQL instances) in this blueprint. When this field is set in Terraform state, a terraform destroy or terraform apply that would delete data storage resources will fail. | bool |
false |
|
| network_config | Shared VPC network configurations to use. If null networks will be created in projects with preconfigured values. | object({…}) |
null |
|
| postgres_database | postgres database. |
string |
"guestbook" |
|
| project_create | Provide values if project creation is needed, uses existing project if null. Parent is in 'folders/nnn' or 'organizations/nnn' format. | object({…}) |
null |
|
| regions | Map of instance_name => location where instances will be deployed. | map(string) |
{…} |
|
| service_encryption_keys | Cloud KMS keys to use to encrypt resources. Provide a key for each reagion configured. | map(string) |
null |
|
| sql_configuration | Cloud SQL configuration. | object({…}) |
{…} |
|
| sql_users | Cloud SQL user emails. | list(string) |
[] |
Outputs
| name | description | sensitive |
|---|---|---|
| bucket | Cloud storage bucket to import/export data from Cloud SQL. | |
| connection_names | Connection name of each instance. | |
| demo_commands | Demo commands. | |
| ips | IP address of each instance. | |
| project_id | ID of the project containing all the instances. | |
| service_account | SQL client service Accounts. |
Test
module "test" {
source = "./fabric/blueprints/data-solutions/cloudsql-multiregion/"
data_eng_principal = "group:dataeng@example.com"
postgres_user_password = "my-root-password"
project_id = "project"
project_create = {
billing_account_id = "123456-123456-123456"
parent = "folders/12345678"
}
prefix = "prefix"
}
# tftest modules=9 resources=44