* Bump copyright notice to 2023 * Delete versions.tf on blueprints * Pin provider to major version 5 * Remove comment * Fix lint * fix bq-ml blueprint readme --------- Co-authored-by: Ludovico Magnocavallo <ludomagno@google.com> Co-authored-by: Julio Castillo <jccb@google.com> |
||
|---|---|---|
| .. | ||
| data-demo | ||
| images | ||
| templates | ||
| README.md | ||
| backend.tf.sample | ||
| datastorage.tf | ||
| kms.tf | ||
| main.tf | ||
| outputs.tf | ||
| serviceaccounts.tf | ||
| variables.tf | ||
| vpc.tf | ||
README.md
Spinning up a foundation data pipeline on Google Cloud using Cloud Storage, Dataflow and BigQuery
Introduction
This repository contains the necessary Terraform modules to securely deploy a basic ETL pipeline that will dump data from a Google Cloud Storage (GCS) bucket to tables in BigQuery.
An ETL pipeline is defined in three steps:
- Extraction: retrieving data from sources.
- Transformation: cleaning the data, putting it into a common format, calculating other fields, taking out duplicates or erroneous records so it can be stored into a target.
- Loading: inserting the formatted data into the target database, data store, data warehouse or data lake.
You can learn more about cloud-based ETL here.
Use cases
Whether you’re transferring from another Cloud Service Provider or you’re taking your first steps into the cloud with Google Cloud, building a data pipeline sets a good foundation to begin deriving insights for your business.
- Anomaly Detection: building data pipelines to identify cyber security threats or fraudulent transactions using machine learning (ML) models.
- Interactive Data Analysis: carry out interactive data analysis with BigQuery BI Engine that enables you to analyze large and complex datasets interactively with sub-second query response time and high concurrency.
- Predictive Forecasting: building solid pipelines to capture real-time data for ML modeling and using it as a forecasting engine for situations ranging from weather predictions to market forecasting.
- Create Machine Learning models: using BigQueryML you can create and execute machine learning models in BigQuery using standard SQL queries. Create a variety of models pre-built into BigQuery that you train with your data.
Architecture

The main components that we would be setting up are:
- Cloud Storage (GCS) bucket: data lake solution to store extracted raw data that must undergo some kind of transformation.
- Cloud Dataflow pipeline: to build fully managed batch and streaming pipelines to transform data stored in GCS buckets ready for processing in the Data Warehouse using Apache Beam.
- BigQuery datasets and tables: to store the transformed data in and query it using SQL, use it to make reports or begin training machine learning models.
- Service accounts (created with least privilege on each resource): one for uploading data into the GCS bucket, one for Orchestration, one for Dataflow instances and one for reading BigQuery tables. You can also configure groups of users to assign them a viewer role on the created resources and the ability to impersonate service accounts to test the Dataflow pipelines before automating them with a tool like Cloud Composer.
For a full list of the resources that will be created, please refer to the github repository for this project. If you're migrating from another Cloud Provider, refer to this documentation to see equivalent services and comparisons in Microsoft Azure and Amazon Web Services
Costs
Pricing Estimates - We have created a sample estimate based on some usage we see from new startups looking to scale. This estimate would give you an idea of how much this deployment would essentially cost per month at this scale and you extend it to the scale you further prefer. Here's the link.
Setup
This solution assumes you already have a project created and set up where you wish to host these resources. If not, and you would like for the project to create a new project as well, please refer to the github repository for instructions.
Prerequisites
- Have an organization set up in Google cloud.
- Have a billing account set up.
- Have an existing project with billing enabled, we’ll call this the service project.
Roles & Permissions
In order to spin up this architecture, you will need to be a user with the “Project owner” IAM role on the existing project:
Note: To grant a user a role, take a look at the Granting and Revoking Access documentation.
Spinning up the architecture
Step 1: Cloning the repository
Click on the button below, sign in if required and when the prompt appears, click on “confirm”.

This will clone the repository to your cloud shell and a screen like this one will appear:

Before you deploy the architecture, make sure you run the following command to move your cloudshell session into your service project:
gcloud config set project [SERVICE_PROJECT_ID]
Once you can see your service project id in the yellow parenthesis, you’re ready to start.
Before we deploy the architecture, you will need the following information:
- The service project ID.
- A unique prefix that you want all the deployed resources to have (for example: awesomestartup). This must be a string with no spaces or tabs.
- A list of Groups with Service Account Token creator role on Service Accounts, eg 'group@domain.com'.
Step 2: Deploying the resources
-
Once you have the required information, head back to the cloud shell editor. Make sure you’re in the following directory:
cloudshell_open/cloud-foundation-fabric/blueprints/data-solutions/gcs-to-bq-with-least-privileges -
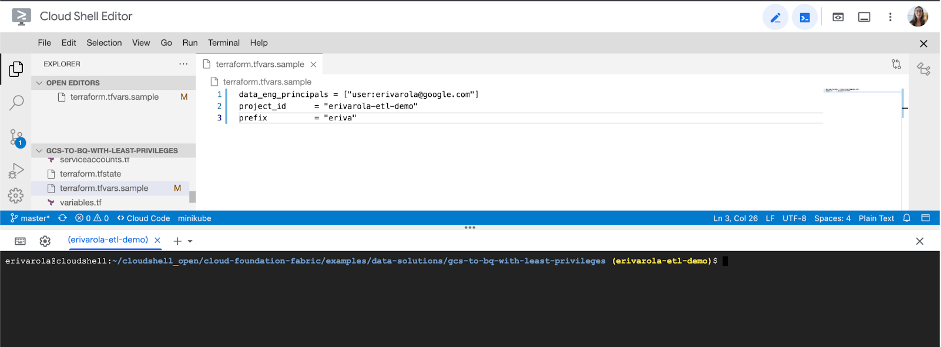
In the editor, edit the terraform.tfvars.sample file with the variables you gathered in the step above.
-
a. Fill in data_eng_principals with the list of Users or Groups to impersonate service accounts.
-
b. Fill in project_id with the service project ID.
-
c. Fill in the prefix with your chosen unique prefix for resources.
-
d. Save the file with Ctrl(or ⌘)+S or by going to File → Save.
-
Then, run the following commands:
terraform init terraform apply -var-file=terraform.tfvars.sample -auto-approve
The resource creation will take a few minutes, at the end this is the output you should expect for successful completion along with a list of the created resources:

Congratulations! You have successfully deployed the foundation for running your first ETL pipeline on Google Cloud.
Testing your architecture
For the purpose of demonstrating how the ETL pipeline flow works, we’ve set up an example pipeline for you to run. First of all, we assume all the steps are run using a user listed on the data_eng_principles variable (or a user that belongs to one of the groups you specified). Authenticate the user using the following command and make sure your active cloudshell session is set to the service project:
gcloud auth application-default login
Follow the instructions in the cloudshell to authenticate the user.
To make the next steps easier, create two environment variables with the service project id and the prefix:
export SERVICE_PROJECT_ID=[SERVICE_PROJECT_ID]
export PREFIX=[PREFIX]
Again, make sure you’re in the following directory:
cloudshell_open/cloud-foundation-fabric/blueprints/data-solutions/gcs-to-bq-with-least-privileges
For the purpose of the example we will import from GCS to Bigquery a CSV file with the following structure:
name,surname,timestamp
We need to create 3 files:
- A person.csv file containing your data in the form name,surname,timestamp. For example: `Eva,Rivarola,1637771951'.
- A person_udf.js containing the UDF javascript file used by the Dataflow template.
- A person_schema.json file containing the table schema used to import the CSV.
An example of those files can be found in the folder ./data-demo. Inside the same repository where you ran the terraform commands.
You can copy the example files into the GCS bucket by running:
gsutil -i gcs-landing@$SERVICE_PROJECT_ID.iam.gserviceaccount.com cp data-demo/* gs://$PREFIX-data
Once this is done, the 3 files necessary to run the Dataflow Job will have been copied to the GCS bucket that was created along with the resources.
Run the following command to start the dataflow job:
gcloud --impersonate-service-account=orchestrator@$SERVICE_PROJECT_ID.iam.gserviceaccount.com dataflow jobs run test_batch_01 \
--gcs-location gs://dataflow-templates/latest/GCS_Text_to_BigQuery \
--project $SERVICE_PROJECT_ID \
--region europe-west1 \
--disable-public-ips \
--subnetwork https://www.googleapis.com/compute/v1/projects/$SERVICE_PROJECT_ID/regions/europe-west1/subnetworks/subnet \
--staging-location gs://$PREFIX-df-tmp \
--service-account-email df-loading@$SERVICE_PROJECT_ID.iam.gserviceaccount.com \
--parameters \
javascriptTextTransformFunctionName=transform,\
JSONPath=gs://$PREFIX-data/person_schema.json,\
javascriptTextTransformGcsPath=gs://$PREFIX-data/person_udf.js,\
inputFilePattern=gs://$PREFIX-data/person.csv,\
outputTable=$SERVICE_PROJECT_ID:datalake.person,\
bigQueryLoadingTemporaryDirectory=gs://$PREFIX-df-tmp
This command will start a dataflow job called test_batch_01 that uses a Dataflow transformation script stored in the public GCS bucket:
gs://dataflow-templates/latest/GCS_Text_to_BigQuery.
The expected output is the following:

Then, if you navigate to Dataflow on the console, you will see the following:

This shows the job you started from the cloudshell is currently running in Dataflow. If you click on the job name, you can see the job graph created and how every step of the Dataflow pipeline is moving along:
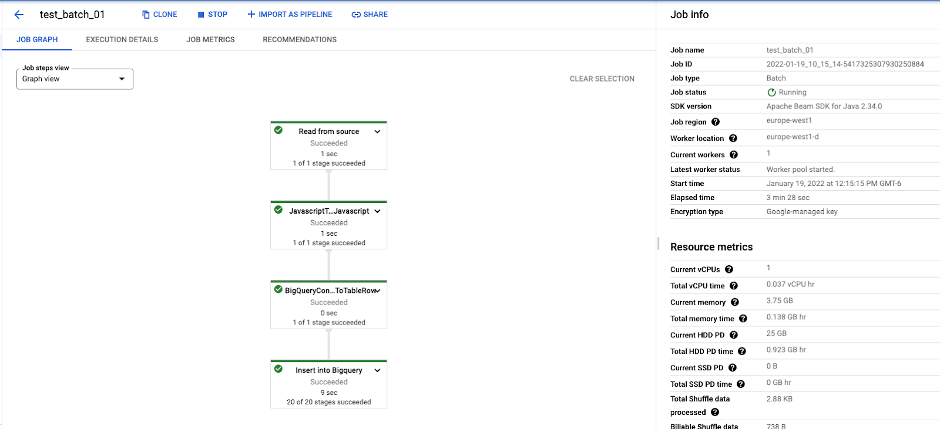
Once the job completes, you can navigate to BigQuery in the console and under SERVICE_PROJECT_ID → datalake → person, you can see the data that was successfully imported into BigQuery through the Dataflow job.
Cleaning up your environment
The easiest way to remove all the deployed resources is to run the following command in Cloud Shell:
terraform destroy
The above command will delete the associated resources so there will be no billable charges made afterwards.
Variables
| name | description | type | required | default |
|---|---|---|---|---|
| prefix | Prefix used for resource names. | string |
✓ | |
| project_config | Provide 'billing_account_id' value if project creation is needed, uses existing 'project_id' if null. Parent is in 'folders/nnn' or 'organizations/nnn' format. If project is created, var.prefix will be used. |
object({…}) |
✓ | |
| cmek_encryption | Flag to enable CMEK on GCP resources created. | bool |
false |
|
| data_eng_principals | Groups with admin/developer role on enabled services and Service Account Token creator role on service accounts in IAM format, eg 'group:group@domain.com'. | list(string) |
[] |
|
| deletion_protection | Prevent Terraform from destroying data storage resources (storage buckets, GKE clusters, CloudSQL instances) in this blueprint. When this field is set in Terraform state, a terraform destroy or terraform apply that would delete data storage resources will fail. | bool |
true |
|
| network_config | Shared VPC network configurations to use. If null networks will be created in projects with preconfigured values. | object({…}) |
{} |
|
| region | The region where resources will be deployed. | string |
"europe-west1" |
|
| vpc_subnet_range | Ip range used for the VPC subnet created for the example. | string |
"10.0.0.0/20" |
Outputs
| name | description | sensitive |
|---|---|---|
| bq_tables | Bigquery Tables. | |
| buckets | GCS bucket Cloud KMS crypto keys. | |
| command_01_gcs | gcloud command to copy data into the created bucket impersonating the service account. | |
| command_02_dataflow | Command to run Dataflow template impersonating the service account. | |
| command_03_bq | BigQuery command to query imported data. | |
| project_id | Project id. | |
| service_accounts | Service account. |
Test
module "test" {
source = "./fabric/blueprints/data-solutions/gcs-to-bq-with-least-privileges/"
project_config = {
billing_account_id = "123456-123456-123456"
parent = "folders/12345678"
project_id = "project-1"
}
prefix = "prefix"
}
# tftest modules=12 resources=43