* wip * wip * wip * wip * wip * discovery * single discovery * page token * batch requests * remove plugin name * streamline * streamline * dynamic routes * dynamic routes * forwarding rules and addresses * batch requests * metrics * notes * notes * streamline * fixes, dump * streamline * remove globals * wip metrics * subnet time series * networks per project plugin * firewall rules timeseries * use names in metric labels * firewall policies timeseries * wip * instances per network timeseries * routes timeseries * custom quota * simpler quota, network peering timeseries * peering timeseries * timeseries names * wip descriptors * metric descriptors * fixes * wip * Use partial for all cf init functions * Add requirements.txt * fix org key mismatch * Fix folder short cli name * Fix instance_networks when iterable is empty * more readability and fixing some strings * replace() -> removeprefix and remove unneeded quoting * setdefault in init()s * Fix next hop type * Remove unneeded fstring * create descriptors * create descriptors log * rename descriptor requests function * non-working metrics implementation (duplicate timeseries batched) * timeseries * fixes * write timseries * fix timeseries plugins * start documenting code * docstrings and comments * docstrings comments and small fixes * rename cf to src * discover nodes instead of just projects * discovery node can be a folder or org * cf entrypoint and fixes * cf deployment * remove old paths * cloud function deploy readme * diagrams * resource ids in example * discovery tool readme * top-level README * Some documentation fixes * Add secondary ranges * Update README.md * add legend to scope diagram * improve description of discovery configuration variable * add comment in example for custom quotas file * rename op_project to monitoring_project * dashboard metric rename wip * Update discover-cai-compute.py * deploy sample dashboard Co-authored-by: Julio Castillo <jccb@google.com> Co-authored-by: Aurélien Legrand <aurelien.legrand01@gmail.com> |
||
|---|---|---|
| .. | ||
| adfs | ||
| apigee | ||
| asset-inventory-feed-remediation | ||
| dns-fine-grained-iam | ||
| dns-shared-vpc | ||
| iam-delegated-role-grants | ||
| network-dashboard | ||
| onprem-sa-key-management | ||
| packer-image-builder | ||
| quota-monitoring | ||
| scheduled-asset-inventory-export-bq | ||
| terraform-enterprise-wif | ||
| unmanaged-instances-healthcheck | ||
| vm-migration | ||
| workload-identity-federation | ||
| README.md | ||
README.md
Operations blueprints
The blueprints in this folder show how to wire together different Google Cloud services to simplify operations, and are meant for testing, or as minimal but sufficiently complete starting points for actual use.
Active Directory Federation Services
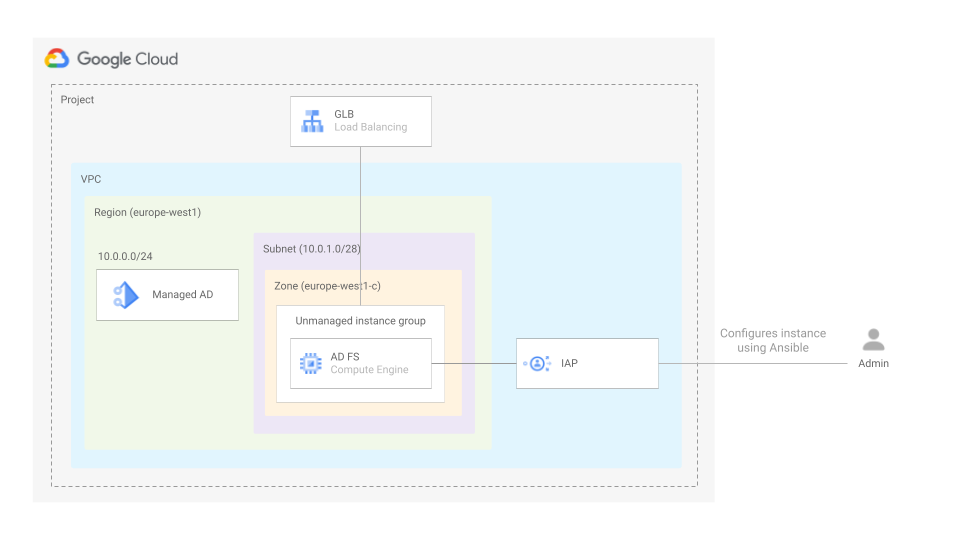 This blueprint Sets up managed AD, creates a server where AD FS will be installed which will also act as admin workstation for AD, and exposes ADFS using GLB. It can also optionally set up a GCP project and VPC if needed
This blueprint Sets up managed AD, creates a server where AD FS will be installed which will also act as admin workstation for AD, and exposes ADFS using GLB. It can also optionally set up a GCP project and VPC if needed
Resource tracking and remediation via Cloud Asset feeds
 This blueprint shows how to leverage Cloud Asset Inventory feeds to stream resource changes in real time, and how to programmatically use the feed change notifications for alerting or remediation, via a Cloud Function wired to the feed PubSub queue.
This blueprint shows how to leverage Cloud Asset Inventory feeds to stream resource changes in real time, and how to programmatically use the feed change notifications for alerting or remediation, via a Cloud Function wired to the feed PubSub queue.
The blueprint's feed tracks changes to Google Compute instances, and the Cloud Function enforces policy compliance on each change so that tags match a set of simple rules. The obvious use case is when instance tags are used to scope firewall rules, but the blueprint can easily be adapted to suit different use cases.
Granular Cloud DNS IAM via Service Directory
 This blueprint shows how to leverage Service Directory and Cloud DNS Service Directory private zones, to implement fine-grained IAM controls on DNS. The blueprint creates a Service Directory namespace, a Cloud DNS private zone that uses it as its authoritative source, service accounts with different levels of permissions, and VMs to test them.
This blueprint shows how to leverage Service Directory and Cloud DNS Service Directory private zones, to implement fine-grained IAM controls on DNS. The blueprint creates a Service Directory namespace, a Cloud DNS private zone that uses it as its authoritative source, service accounts with different levels of permissions, and VMs to test them.
Granular Cloud DNS IAM for Shared VPC
 This blueprint shows how to create reusable and modular Cloud DNS architectures, by provisioning dedicated Cloud DNS instances for application teams that want to manage their own DNS records, and configuring DNS peering to ensure name resolution works in a common Shared VPC.
This blueprint shows how to create reusable and modular Cloud DNS architectures, by provisioning dedicated Cloud DNS instances for application teams that want to manage their own DNS records, and configuring DNS peering to ensure name resolution works in a common Shared VPC.
Delegated Role Grants
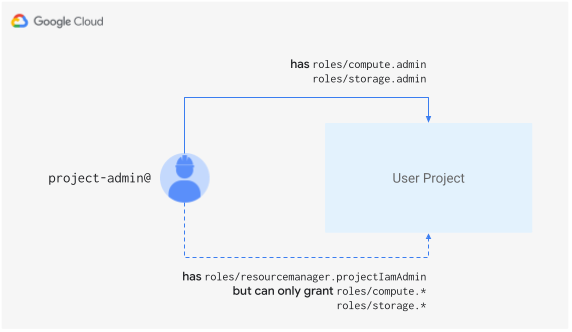 This blueprint shows how to use delegated role grants to restrict service usage.
This blueprint shows how to use delegated role grants to restrict service usage.
Network Dashboard
 This blueprint provides an end-to-end solution to gather some GCP Networking quotas and limits (that cannot be seen in the GCP console today) and display them in a dashboard. The goal is to allow for better visibility of these limits, facilitating capacity planning and avoiding hitting these limits..
This blueprint provides an end-to-end solution to gather some GCP Networking quotas and limits (that cannot be seen in the GCP console today) and display them in a dashboard. The goal is to allow for better visibility of these limits, facilitating capacity planning and avoiding hitting these limits..
On-prem Service Account key management
This blueprint shows how to manage IAM Service Account Keys by manually generating a key pair and uploading the public part of the key to GCP.
Packer image builder
 This blueprint shows how to deploy infrastructure for a Compute Engine image builder based on Hashicorp's Packer tool.
This blueprint shows how to deploy infrastructure for a Compute Engine image builder based on Hashicorp's Packer tool.
Compute Engine quota monitoring
 This blueprint shows a practical way of collecting and monitoring Compute Engine resource quotas via Cloud Monitoring metrics as an alternative to the recently released built-in quota metrics. A simple alert on quota thresholds is also part of the blueprint.
This blueprint shows a practical way of collecting and monitoring Compute Engine resource quotas via Cloud Monitoring metrics as an alternative to the recently released built-in quota metrics. A simple alert on quota thresholds is also part of the blueprint.
Scheduled Cloud Asset Inventory Export to Bigquery
 This blueprint shows how to leverage the Cloud Asset Inventory Exporting to Bigquery feature, to keep track of your organization's assets over time storing information in Bigquery. Data stored in Bigquery can then be used for different purposes like dashboarding or analysis.
This blueprint shows how to leverage the Cloud Asset Inventory Exporting to Bigquery feature, to keep track of your organization's assets over time storing information in Bigquery. Data stored in Bigquery can then be used for different purposes like dashboarding or analysis.
Workload identity federation for Terraform Enterprise workflow
 This blueprint shows how to configure Wokload Identity Federation between Terraform Cloud/Enterprise instance and Google Cloud.
This blueprint shows how to configure Wokload Identity Federation between Terraform Cloud/Enterprise instance and Google Cloud.
TCP healthcheck for unmanaged GCE instances
 This blueprint shows how to leverage Serverless VPC Access and Cloud Functions to organize a highly performant TCP healtheck for unmanaged GCE instances.
This blueprint shows how to leverage Serverless VPC Access and Cloud Functions to organize a highly performant TCP healtheck for unmanaged GCE instances.
Migrate for Compute Engine (v5)
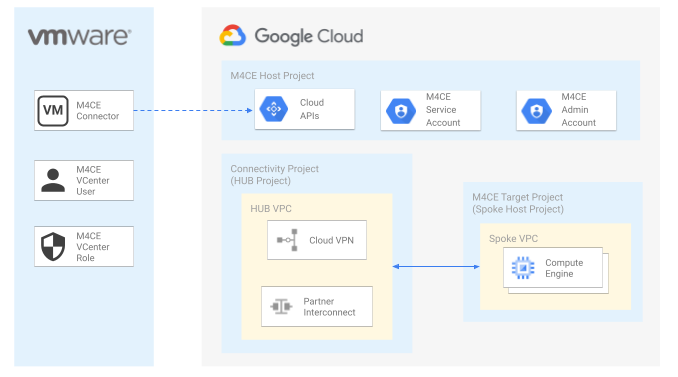 This set of blueprints shows how to deploy Migrate for Compute Engine (v5) on top of existing Cloud Foundations on different scenarios. An blueprint on how to deploy the M4CE connector on VMWare ESXi is also part of the blueprints.
This set of blueprints shows how to deploy Migrate for Compute Engine (v5) on top of existing Cloud Foundations on different scenarios. An blueprint on how to deploy the M4CE connector on VMWare ESXi is also part of the blueprints.
Configuring Workload Identity Federation from apps running on Azure
 This blueprint shows how to set up everything, both in Azure and Google Cloud, so a workload in Azure can access Google Cloud resources without a service account key. This will be possible by configuring workload identity federation to trust access tokens generated for a specific application in an Azure Active Directory (AAD) tenant.
This blueprint shows how to set up everything, both in Azure and Google Cloud, so a workload in Azure can access Google Cloud resources without a service account key. This will be possible by configuring workload identity federation to trust access tokens generated for a specific application in an Azure Active Directory (AAD) tenant.