11 KiB
4 Optimizations
The above sections describe a secure messaging protocol that can handle all normal situations between two blockchains. It guarantees that all messages are processed exactly once and in order, and provides a mechanism for non-blocking atomic transactions spanning two blockchains. However, to increase efficiency over millions of messages with many possible failure modes on both sides of the connection, we can extend the protocol. These extensions allow us to clean up the receipt queue to avoid state bloat, as well as more gracefully recover from cases where large numbers of messages are not being relayed, or other failure modes in the remote chain.
4.1 Timeouts
Sometimes it is desirable to have some timeout, an upper limit to how long you will wait for a transaction to be processed before considering it an error. At the same time, this is an obvious attack vector for a double spend, just delaying the relay of the receipt or waiting to send the message in the first place and then relaying it right after the cutoff to take advantage of different local clocks on the two chains.
One solution to this is to include a timeout in the IBC message itself. When sending it, one can specify a block height or timestamp on the receiving chain after which it is no longer valid. If the message is posted before the cutoff, it will be processed normally. If it is posted after that cutoff, it will be a guaranteed error. Note that to make this secure, the timeout must be relative to a condition on the receiving chain, and the sending chain must have proof of the state of the receiving chain after the cutoff.
For a sending chain A and a receiving chain B, with k=(_, _, i) for A:qB.send or B:qA.receipt we currently have the following guarantees:
A:Mk,v,h = ∅ if message i was not sent before height h
A:Mk,v,h = ∅ if message i was sent and receipt received before height h (and the receipts for all messages j < i were also handled)
A:Mk,v,h ≠ ∅ otherwise (message result is not yet processed)
B:Mk,v,h = ∅ if message i was not received before height h
B:Mk,v,h ≠ ∅ if message i was received before height h (and all messages j < i were received)
Based on these guarantees, we can make a few modifications of the above protocol to allow us to prove timeouts, by adding some fields to the messages in the send queue, and defining an expired function that returns true iff h > maxHeight or timestamp(Hh ) > maxTime.
Vsend = (maxHeight, maxTime, type, data)
expired(Hh ,Vsend ) ⇒ [true|false]
We then update message handling in IBCreceive, so it doesn't even call the handler function if the timeout was reached, but rather directly writes and error in the receipt queue:
IBCreceive:
- expired(latestHeader, v) ⇒ push(qS.receipt , (None, TimeoutError)),
- v = (_, _, type, data) ⇒ (result, err) := ftype(data); push(qS.receipt , (result, err));
and add a new IBCtimeout function to accept tail proofs to demonstrate that the message was not processed at some given header on the recipient chain. This allows the sender chain to assert timeouts locally.
S:IBCtimeout(A, Mk,v,h) ⇒ match
- qA.send = ∅ ⇒ Error("unregistered sender"),
- k = (_, send, _) ⇒ Error("must be a receipt"),
- k = (d, _, _) and d ≠ S ⇒ Error("sent to a different chain"),
- Hh ∉ TA ⇒ Error("must submit header for height h"),
- not valid(Hh , Mk,v,h ) ⇒ Error("invalid merkle proof"),
- k = (S, receipt, tail) ⇒ match
- tail ≥ head(qS.send ) ⇒ Error("receipt exists, no timeout proof")
- not expired(peek(qS.send )) ⇒ Error("message timeout not yet reached")
- default ⇒ (_, _, type, data) := pop(qS.send ); rollbacktype(data); Success
- default ⇒ Error("must be a tail proof")
which processes timeouts in order, and adds one more condition to the queues:
A:Mk,v,h = ∅ if message i was sent and timeout proven before height h (and the receipts for all messages j < i were also handled)
Now chain A can rollback all transactions that were blocked by this flood of unrelayed messages, without waiting for chain B to process them and return a receipt. Adding reasonable timeouts to all packets allows us to gracefully handle any errors with the IBC relay processes, or a flood of unrelayed "spam" IBC packets. If a blockchain requires a timeout on all messages, and imposes some reasonable upper limit (or just assigns it automatically), we can guarantee that if message i is not processed by the upper limit of the timeout period, then all previous messages must also have either been processed or reached the timeout period.
Note that in order to avoid any possible "double-spend" attacks, the timeout algorithm requires that the destination chain is running and reachable. One can prove nothing in a complete network partition, and must wait to connect; the timeout must be proven on the recipient chain, not simply the absence of a response on the sending chain.
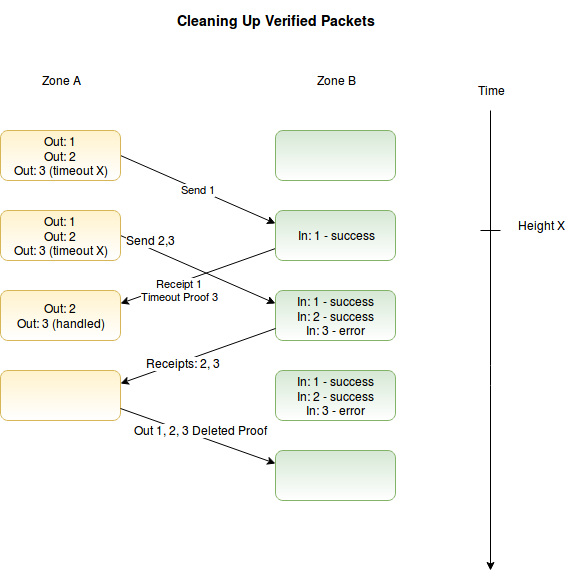
4.2 Clean up
While we clean up the send queue upon getting a receipt, if left to run indefinitely, the receipt queues could grow without limit and create a major storage requirement for the chains. However, we must not delete receipts until they have been proven to be processed by the sending chain, or we lose important information and sacrifice reliability.
The observant reader may also notice, that when we perform the timeout on the sending chain, we do not update the receipt queue on the receiving chain, and now it is blocked waiting for a message i, which no longer exists on the sending chain. We can update the guarantees of the receipt queue as follows to allow us to handle both:
B:Mk,v,h = ∅ if message i was not received before height h
B:Mk,v,h = ∅ if message i was provably resolved on the sending chain before height h
B:Mk,v,h ≠ ∅ otherwise (if message i was processed before height h, and no ack of receipt from the sending chain)
Consider a connection where many messages have been sent, and their receipts processed on the sending chain, either explicitly or through a timeout. We wish to quickly advance over all the processed messages, either for a normal cleanup, or to prepare the queue for normal use again after timeouts.
Through the definition of the send queue above, we see that all messages i < head have been fully processed, and all messages head <= i < tail are awaiting processing. By proving a much advanced head of the send queue, we can demonstrate that the sending chain already handled all messages. Thus, we can safely advance our local receipt queue to the new head of the remote send queue.
S:IBCcleanup(A, Mk,v,h) ⇒ match
- qA.receipt = ∅ ⇒ Error("unknown sender"),
- k = (_, send, _) ⇒ Error("must be for the send queue"),
- k = (d, _, _) and d ≠ S ⇒ Error("sent to a different chain"),
- k ≠ (_, _, head) ⇒ Error("Need a proof of the head of the queue"),
- Hh ∉ TA ⇒ Error("must submit header for height h"),
- not valid(Hh ,Mk,v,h ) ⇒ Error("invalid merkle proof"),
- head := v ⇒ match
- head <= head(qA.receipt) ⇒ Error("cleanup must go forward"),
- default ⇒ advance(qA.receipt , head); Success
This allows us to invoke the IBCcleanup function to resolve all outstanding messages up to and including head with one merkle proof. Note that this handles both recovering from a blocked queue after timeouts, as well as a routine cleanup method to recover space. In the cleanup scenario, we assume that there may also be a number of messages that have been processed by the receiving chain, but not yet posted to the sending chain, tail(B:qA.reciept ) > head(A:qB.send ). As such, the advance function must not modify any messages between the head and the tail.
4.3 Handling Byzantine Failures
While every message is guaranteed reliable in the face of malicious nodes or relays, all guarantees break down when the entire blockchain on the other end of the connection exhibits byzantine faults. These can be in two forms:
- failures of the consensus mechanism (reversing "final" blocks)
- failure at the application level (not performing the action defined by the message).
The IBC protocol can only detect byzantine faults at the consensus level, and is designed to halt with an error upon detecting any such fault. That is, if it ever sees two different headers for the same height (or any evidence that headers belong to different forks), then it must freeze the connection immediately. The resolution of the fault must be handled by the blockchain governance, as this is a serious incident and cannot be predefined.
If there is a big divide in the remote chain and they split eg. 60-40 as to the direction of the chain, then the light-client protocol will refuses to follow either fork. If both sides declare a hard fork and continue with new validator sets that are not compatible with the consensus engine (they don't have ⅔ support from the previous block), then users will have to manually tell their local client which chain to follow (or fork and follow both with different IDs).
The IBC protocol doesn't have the option to follow both chains as the queue and associated state must map to exactly one remote chain. In a fork, the chain can continue the connection with one fork, and optionally make a fresh connection with the other fork (which will also have to adjust internally to wipe its view of the connection clean).
The other major byzantine action is at the application level. Let us assume messages represent transfer of value. If chain A sends a message with X tokens to chain B, then it promises to remove X tokens from the local supply. And if chain B handles this message with a success code, it promises to credit X tokens to the account mentioned in the message. What if A isn't actually removing tokens from the supply, or if B is not actually crediting accounts?
Such application level issues cannot be proven in a generic sense, but must be handled individually by each application. The activity should be provable in some manner (as it is all in an auditable blockchain), but there are too many failure modes to attempt to enumerate, so we rely on the vigilance of the participants in the extremely rare case of a rogue blockchain. Of course, this misbehavior is provable and can negatively impact the value of the offending chain, providing economic incentives for any normal chain not to run malicious applications over IBC.