20 KiB
Data Platform
The Data Platform builds on top of your foundations to create and set up projects (and related resources) to be used for your data platform.
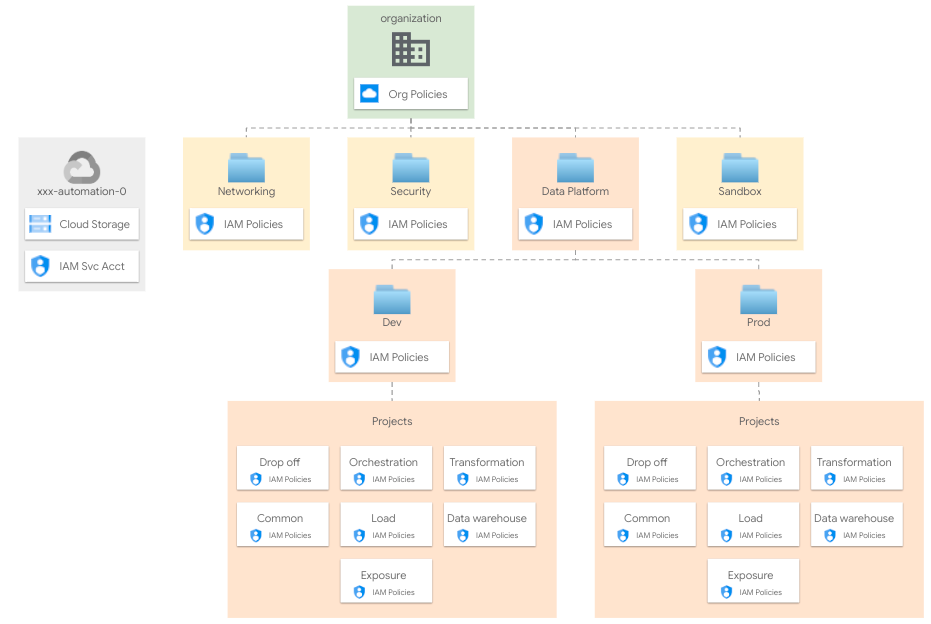
Design overview and choices
A more comprehensive description of the Data Platform architecture and approach can be found in the Data Platform module README. The module is wrapped and configured here to leverage the FAST flow.
The Data Platform creates projects in a well-defined context, usually an ad-hoc folder managed by the resource management setup. Resources are organized by environment within this folder.
Across different data layers environment-specific projects are created to separate resources and IAM roles.
The Data Platform manages:
- project creation
- API/Services enablement
- service accounts creation
- IAM role assignment for groups and service accounts
- KMS keys roles assignment
- Shared VPC attachment and subnet IAM binding
- project-level organization policy definitions
- billing setup (billing account attachment and budget configuration)
- data-related resources in the managed projects
User groups
As per our GCP best practices the Data Platform relies on user groups to assign roles to human identities. These are the specific groups used by the Data Platform and their access patterns, from the module documentation:
- Data Engineers They handle and run the Data Hub, with read access to all resources in order to troubleshoot possible issues with pipelines. This team can also impersonate any service account.
- Data Analysts. They perform analysis on datasets, with read access to the data warehouse Curated or Confidential projects depending on their privileges.
- Data Security:. They handle security configurations related to the Data Hub. This team has admin access to the common project to configure Cloud DLP templates or Data Catalog policy tags.
| Group | Landing | Load | Transformation | Data Warehouse Landing | Data Warehouse Curated | Data Warehouse Confidential | Orchestration | Common |
|---|---|---|---|---|---|---|---|---|
| Data Engineers | ADMIN |
ADMIN |
ADMIN |
ADMIN |
ADMIN |
ADMIN |
ADMIN |
ADMIN |
| Data Analysts | - | - | - | - | - | READ |
- | - |
| Data Security | - | - | - | - | - | - | - | - |
Network
A Shared VPC is used here, either from one of the FAST networking stages (e.g. hub and spoke via VPN) or from an external source.
Encryption
Cloud KMS crypto keys can be configured wither from the FAST security stage or from an external source. This step is optional and depends on customer policies and security best practices.
To configure the use of Cloud KMS on resources, you have to specify the key id on the service_encryption_keys variable. Key locations should match resource locations.
Data Catalog
Data Catalog helps you to document your data entry at scale. Data Catalog relies on tags and tag template to manage metadata for all data entries in a unified and centralized service. To implement column-level security on BigQuery, we suggest to use Tags and Tag templates.
The default configuration will implement 3 tags:
3_Confidential: policy tag for columns that include very sensitive information, such as credit card numbers.2_Private: policy tag for columns that include sensitive personal identifiable information (PII) information, such as a person's first name.1_Sensitive: policy tag for columns that include data that cannot be made public, such as the credit limit.
Anything that is not tagged is available to all users who have access to the data warehouse.
You can configure your tags and roles associated by configuring the data_catalog_tags variable. We suggest using the "Best practices for using policy tags in BigQuery" article as a guide to designing your tags structure and access pattern. By default, no groups has access to tagged data.
VPC-SC
As is often the case in real-world configurations, VPC-SC is needed to mitigate data exfiltration. VPC-SC can be configured from the FAST security stage. This step is optional, but highly recommended, and depends on customer policies and security best practices.
To configure the use of VPC-SC on the data platform, you have to specify the data platform project numbers on the vpc_sc_perimeter_projects.dev variable on FAST security stage.
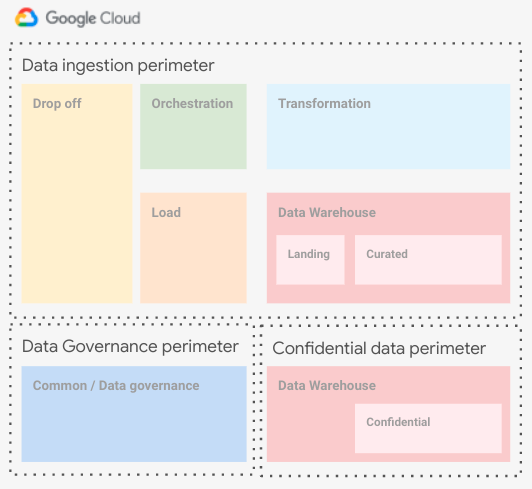
In the case your Data Warehouse need to handle confidential data and you have the requirement to separate them deeply from other data and IAM is not enough, the suggested configuration is to keep the confidential project in a separate VPC-SC perimeter with the adequate ingress/egress rules needed for the load and transformation service account. Below you can find an high level diagram describing the configuration.
How to run this stage
This stage is meant to be executed after the FAST "foundational" stages: bootstrap, resource management, security and networking stages.
It's of course possible to run this stage in isolation, refer to the Running in isolation section below for details.
Before running this stage, you need to make sure you have the correct credentials and permissions, and localize variables by assigning values that match your configuration.
Provider and Terraform variables
As all other FAST stages, the mechanism used to pass variable values and pre-built provider files from one stage to the next is also leveraged here.
The commands to link or copy the provider and terraform variable files can be easily derived from the stage-links.sh script in the FAST root folder, passing it a single argument with the local output files folder (if configured) or the GCS output bucket in the automation project (derived from stage 0 outputs). The following examples demonstrate both cases, and the resulting commands that then need to be copy/pasted and run.
../../../stage-links.sh ~/fast-config
# copy and paste the following commands for '3-data-platform'
ln -s ~/fast-config/providers/3-data-platform-providers.tf ./
ln -s ~/fast-config/tfvars/0-globals.auto.tfvars.json ./
ln -s ~/fast-config/tfvars/0-bootstrap.auto.tfvars.json ./
ln -s ~/fast-config/tfvars/1-resman.auto.tfvars.json ./
ln -s ~/fast-config/tfvars/2-networking.auto.tfvars.json ./
ln -s ~/fast-config/tfvars/2-security.auto.tfvars.json ./
../../../stage-links.sh gs://xxx-prod-iac-core-outputs-0
# copy and paste the following commands for '3-data-platform'
gcloud alpha storage cp gs://xxx-prod-iac-core-outputs-0/providers/3-data-platform-providers.tf ./
gcloud alpha storage cp gs://xxx-prod-iac-core-outputs-0/tfvars/0-globals.auto.tfvars.json ./
gcloud alpha storage cp gs://xxx-prod-iac-core-outputs-0/tfvars/0-bootstrap.auto.tfvars.json ./
gcloud alpha storage cp gs://xxx-prod-iac-core-outputs-0/tfvars/1-resman.auto.tfvars.json ./
gcloud alpha storage cp gs://xxx-prod-iac-core-outputs-0/tfvars/2-networking.auto.tfvars.json ./
gcloud alpha storage cp gs://xxx-prod-iac-core-outputs-0/tfvars/2-security.auto.tfvars.json ./
Impersonating the automation service account
The preconfigured provider file uses impersonation to run with this stage's automation service account's credentials. The gcp-devops and organization-admins groups have the necessary IAM bindings in place to do that, so make sure the current user is a member of one of those groups.
Variable configuration
Variables in this stage -- like most other FAST stages -- are broadly divided into three separate sets:
- variables which refer to global values for the whole organization (org id, billing account id, prefix, etc.), which are pre-populated via the
0-globals.auto.tfvars.jsonfile linked or copied above - variables which refer to resources managed by previous stage, which are prepopulated here via the
*.auto.tfvars.jsonfiles linked or copied above - and finally variables that optionally control this stage's behaviour and customizations, and can to be set in a custom
terraform.tfvarsfile
The full list can be found in the Variables table at the bottom of this document.
Running the stage
Once provider and variable values are in place and the correct user is configured, the stage can be run:
terraform init
terraform apply
Running in isolation
This stage can be run in isolation by providing the necessary variables, but it's really meant to be used as part of the FAST flow after the "foundational stages" (0-bootstrap, 1-resman, 2-networking and 2-security).
When running in isolation, the following roles are needed on the principal used to apply Terraform:
- on the organization or network folder level
roles/xpnAdminor a custom role which includes the following permissions"compute.organizations.enableXpnResource","compute.organizations.disableXpnResource","compute.subnetworks.setIamPolicy",
- on each folder where projects are created
"roles/logging.admin""roles/owner""roles/resourcemanager.folderAdmin""roles/resourcemanager.projectCreator"
- on the host project for the Shared VPC
"roles/browser""roles/compute.viewer"
- on the organization or billing account
roles/billing.admin
The VPC host project, VPC and subnets should already exist.
Demo pipeline
The application layer is out of scope of this script. As a demo purpuse only, several Cloud Composer DAGs are provided. Demos will import data from the landing area to the DataWarehouse Confidential dataset suing different features.
You can find examples in the [demo](../../../../blueprints/data-solutions/data-platform-foundations/demo) folder.
Files
| name | description | modules | resources |
|---|---|---|---|
| main.tf | Data Platform. | data-platform-foundations |
|
| outputs.tf | Output variables. | google_storage_bucket_object · local_file |
|
| variables.tf | Terraform Variables. |
Variables
| name | description | type | required | default | producer |
|---|---|---|---|---|---|
| automation | Automation resources created by the bootstrap stage. | object({…}) |
✓ | 0-bootstrap |
|
| billing_account | Billing account id. If billing account is not part of the same org set is_org_level to false. |
object({…}) |
✓ | 0-bootstrap |
|
| folder_ids | Folder to be used for the networking resources in folders/nnnn format. | object({…}) |
✓ | 1-resman |
|
| host_project_ids | Shared VPC project ids. | object({…}) |
✓ | 2-networking |
|
| organization | Organization details. | object({…}) |
✓ | 00-globals |
|
| prefix | Unique prefix used for resource names. Not used for projects if 'project_create' is null. | string |
✓ | 00-globals |
|
| composer_config | Cloud Composer config. | object({…}) |
{…} |
||
| data_catalog_tags | List of Data Catalog Policy tags to be created with optional IAM binging configuration in {tag => {ROLE => [MEMBERS]}} format. | map(object({…})) |
{…} |
||
| deletion_protection | Prevent Terraform from destroying data storage resources (storage buckets, GKE clusters, CloudSQL instances) in this blueprint. When this field is set in Terraform state, a terraform destroy or terraform apply that would delete data storage resources will fail. | bool |
true |
||
| groups_dp | Data Platform groups. | map(string) |
{…} |
||
| location | Location used for multi-regional resources. | string |
"eu" |
||
| network_config_composer | Network configurations to use for Composer. | object({…}) |
{…} |
||
| outputs_location | Path where providers, tfvars files, and lists for the following stages are written. Leave empty to disable. | string |
null |
||
| project_config | Provide projects configuration. | object({…}) |
{} |
||
| project_services | List of core services enabled on all projects. | list(string) |
[…] |
||
| project_suffix | Suffix used only for project ids. | string |
null |
||
| region | Region used for regional resources. | string |
"europe-west1" |
||
| service_encryption_keys | Cloud KMS to use to encrypt different services. Key location should match service region. | object({…}) |
null |
||
| subnet_self_links | Shared VPC subnet self links. | object({…}) |
null |
2-networking |
|
| vpc_self_links | Shared VPC self links. | object({…}) |
null |
2-networking |
Outputs
| name | description | sensitive | consumers |
|---|---|---|---|
| bigquery_datasets | BigQuery datasets. | ||
| demo_commands | Demo commands. | ||
| gcs_buckets | GCS buckets. | ||
| kms_keys | Cloud MKS keys. | ||
| projects | GCP Projects information. | ||
| vpc_network | VPC network. | ||
| vpc_subnet | VPC subnetworks. |