26 KiB
VRT: A Video Restoration Transformer
arxiv | supplementary | pretrained models | visual results | original project page


This is the readme of "VRT: A Video Restoration Transformer" (arxiv, supp, pretrained models, visual results). VRT achieves state-of-the-art performance (up to 2.16dB) in
- video SR (REDS, Vimeo90K, Vid4 and UDM10)
- video deblurring (GoPro, DVD and REDS)
- video denoising (DAVIS and Set8)
- video frame interpolation (Vimeo90K, UCF101, DAVIS)
- space-time video SR (Vimeo90K, Vid4)





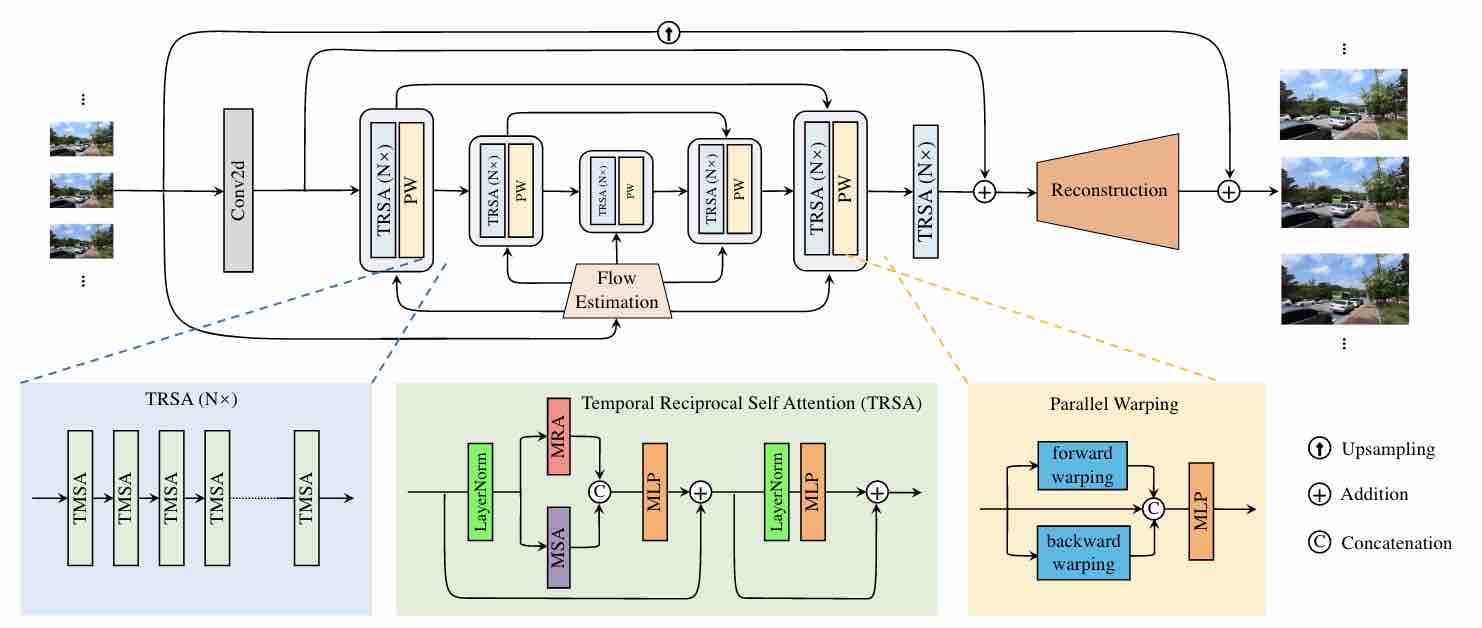
Video restoration (e.g., video super-resolution) aims to restore high-quality frames from low-quality frames. Different from single image restoration, video restoration generally requires to utilize temporal information from multiple adjacent but usually misaligned video frames. Existing deep methods generally tackle with this by exploiting a sliding window strategy or a recurrent architecture, which either is restricted by frame-by-frame restoration or lacks long-range modelling ability. In this paper, we propose a Video Restoration Transformer (VRT) with parallel frame prediction and long-range temporal dependency modelling abilities. More specifically, VRT is composed of multiple scales, each of which consists of two kinds of modules: temporal mutual self attention (TMSA) and parallel warping. TMSA divides the video into small clips, on which mutual attention is applied for joint motion estimation, feature alignment and feature fusion, while self-attention is used for feature extraction. To enable cross-clip interactions, the video sequence is shifted for every other layer. Besides, parallel warping is used to further fuse information from neighboring frames by parallel feature warping. Experimental results on three tasks, including video super-resolution, video deblurring, video denoising, video frame interpolation and space-time video super-resolution, demonstrate that VRT outperforms the state-of-the-art methods by large margins (up to 2.16 dB) on nine benchmark datasets.
Contents
Requirements
- Python 3.8, PyTorch >= 1.9.1
- Requirements: see requirements.txt
- Platforms: Ubuntu 18.04, cuda-11.1
Quick Testing
Following commands will download pretrained models and test datasets automatically (except Vimeo-90K testing set). If out-of-memory, try to reduce --tile at the expense of slightly decreased performance.
You can also try to test it on Colab ![]() , but the results may be slightly different due to
, but the results may be slightly different due to --tile difference.
# download code
git clone https://github.com/JingyunLiang/VRT
cd VRT
pip install -r requirements.txt
# 001, video sr trained on REDS (6 frames), tested on REDS4
python main_test_vrt.py --task 001_VRT_videosr_bi_REDS_6frames --folder_lq testsets/REDS4/sharp_bicubic --folder_gt testsets/REDS4/GT --tile 40 128 128 --tile_overlap 2 20 20
# 002, video sr trained on REDS (16 frames), tested on REDS4
python main_test_vrt.py --task 002_VRT_videosr_bi_REDS_16frames --folder_lq testsets/REDS4/sharp_bicubic --folder_gt testsets/REDS4/GT --tile 40 128 128 --tile_overlap 2 20 20
# 003, video sr trained on Vimeo (bicubic), tested on Vid4 and Vimeo
python main_test_vrt.py --task 003_VRT_videosr_bi_Vimeo_7frames --folder_lq testsets/Vid4/BIx4 --folder_gt testsets/Vid4/GT --tile 32 128 128 --tile_overlap 2 20 20
python main_test_vrt.py --task 003_VRT_videosr_bi_Vimeo_7frames --folder_lq testsets/vimeo90k/vimeo_septuplet_matlabLRx4/sequences --folder_gt testsets/vimeo90k/vimeo_septuplet/sequences --tile 8 0 0 --tile_overlap 0 20 20
# 004, video sr trained on Vimeo (blur-downsampling), tested on Vid4, UDM10 and Vimeo
python main_test_vrt.py --task 004_VRT_videosr_bd_Vimeo_7frames --folder_lq testsets/Vid4/BDx4 --folder_gt testsets/Vid4/GT --tile 32 128 128 --tile_overlap 2 20 20
python main_test_vrt.py --task 004_VRT_videosr_bd_Vimeo_7frames --folder_lq testsets/UDM10/BDx4 --folder_gt testsets/UDM10/GT --tile 32 128 128 --tile_overlap 2 20 20
python main_test_vrt.py --task 004_VRT_videosr_bd_Vimeo_7frames --folder_lq testsets/vimeo90k/vimeo_septuplet_BDLRx4/sequences --folder_gt testsets/vimeo90k/vimeo_septuplet/sequences --tile 8 0 0 --tile_overlap 0 20 20
# 005, video deblurring trained and tested on DVD
python main_test_vrt.py --task 005_VRT_videodeblurring_DVD --folder_lq testsets/DVD10/test_GT_blurred --folder_gt testsets/DVD10/test_GT --tile 12 256 256 --tile_overlap 2 20 20
# 006, video deblurring trained and tested on GoPro
python main_test_vrt.py --task 006_VRT_videodeblurring_GoPro --folder_lq testsets/GoPro11/test_GT_blurred --folder_gt testsets/GoPro11/test_GT --tile 18 192 192 --tile_overlap 2 20 20
# 007, video deblurring trained on REDS, tested on REDS4
python main_test_vrt.py --task 007_VRT_videodeblurring_REDS --folder_lq testsets/REDS4/blur --folder_gt testsets/REDS4/GT --tile 12 256 256 --tile_overlap 2 20 20
# 008, video denoising trained on DAVIS (noise level 0-50), tested on Set8 and DAVIS
python main_test_vrt.py --task 008_VRT_videodenoising_DAVIS --sigma 10 --folder_lq testsets/Set8 --folder_gt testsets/Set8 --tile 12 256 256 --tile_overlap 2 20 20
python main_test_vrt.py --task 008_VRT_videodenoising_DAVIS --sigma 10 --folder_lq testsets/DAVIS-test --folder_gt testsets/DAVIS-test --tile 12 256 256 --tile_overlap 2 20 20
# 009, video frame interpolation trained on Vimeo (single frame interpolation), tested on Viemo, UCF101 and DAVIS-train
python main_test_vrt.py --task 009_VRT_videofi_Vimeo_4frames --folder_lq testsets/vimeo90k/vimeo_septuplet/sequences --folder_gt testsets/vimeo90k/vimeo_septuplet/sequences --tile 0 0 0 --tile_overlap 0 0 0
python main_test_vrt.py --task 009_VRT_videofi_Vimeo_4frames --folder_lq testsets/UCF101 --folder_gt testsets/UCF101 --tile 0 0 0 --tile_overlap 0 0 0
python main_test_vrt.py --task 009_VRT_videofi_Vimeo_4frames --folder_lq testsets/DAVIS-train --folder_gt testsets/DAVIS-train --tile 0 256 256 --tile_overlap 0 20 20
# 010, space-time video sr, using pretrained models from 003 and 009, tested on Vid4 and Viemo
# Please refer to 003 and 009
# test on your own datasets (an example)
python main_test_vrt.py --task 001_VRT_videosr_bi_REDS_6frames --folder_lq testsets/your/own --tile 40 128 128 --tile_overlap 2 20 20
All visual results of VRT can be downloaded here.
Training
The training and testing sets are as follows (see the supplementary for a detailed introduction of all datasets). For better I/O speed, use commands like python scripts/data_preparation/create_lmdb.py --dataset reds to convert .png datasets to .lmdb datasets.
Note: You do NOT need to prepare the datasets if you just want to test the model. main_test_vrt.py will download the testing set automaticaly.
| Task | Training Set | Testing Set | Pretrained Model and Visual Results of VRT |
|---|---|---|---|
| video SR (setting 1, BI) | REDS sharp & sharp_bicubic (266 videos, 266000 frames: train + val except REDS4) *Use regroup_reds_dataset.py to regroup and rename REDS val set |
REDS4 (4 videos, 400 frames: 000, 011, 015, 020 of REDS) | here |
| video SR (setting 2 & 3, BI & BD) | Vimeo90K (64612 seven-frame videos as in sep_trainlist.txt) * Use generate_LR_Vimeo90K.m and generate_LR_Vimeo90K_BD.m to generate LR frames for bicubic and blur-downsampling VSR, respectively. |
Vimeo90K-T (the rest 7824 7-frame videos) + Vid4 (4 videos) + UDM10 (10 videos) *Use prepare_UDM10.py to regroup and rename the UDM10 dataset |
here |
| video deblurring (setting 1, motion blur) | DVD (61 videos, 5708 frames) *Use prepare_DVD.py to regroup and rename the dataset. |
DVD (10 videos, 1000 frames) *Use evaluate_video_deblurring.m for final evaluation. |
here |
| video deblurring (setting 2, motion blur) | GoPro (22 videos, 2103 frames) *Use prepare_GoPro_as_video.py to regroup and rename the dataset. |
GoPro (11 videos, 1111 frames) *Use evaluate_video_deblurring.m for final evaluation. |
here |
| video deblurring (setting 3, motion blur) | REDS sharp & blur (266 videos, 266000 frames: train & val except REDS4) *Use regroup_reds_dataset.py to regroup and rename REDS val set. Note that it shares the same HQ frames as in VSR. |
REDS4 (4 videos, 400 frames: 000, 011, 015, 020 of REDS) | here |
| video denoising (Gaussian noise) | DAVIS-2017 (90 videos, 6208 frames) *Use all files in DAVIS/JPEGImages/480p |
DAVIS-2017-test (30 videos) + Set8 (8 videos: tractor, touchdown, park_joy and sunflower selected from DERF + hypersmooth, motorbike, rafting and snowboard from GOPRO_540P) | here |
| video frame interpolation (single-frame interpolation) | Vimeo90K (64612 seven-frame videos as in sep_trainlist.txt) |
Vimeo90K-T (the rest 7824 7-frame videos) + UCF101 (100 videos, 100 quintuples) + DAVIS-2017 (90 videos, 6208 frames, 2849 quintuples) *For DAVIS-2017, use all files in DAVIS/JPEGImages/480p |
here |
| space-time video SR | Not trained. Using pretrianed models 003 and 009. | Vimeo90K-T (the rest 7824 7-frame videos) + Vid4 (4 videos) *Using fast/medium/slow splits in data/meta_info. |
here |
Run following commands for training:
# download code
git clone https://github.com/cszn/KAIR
cd KAIR
pip install -r requirements.txt
# 001, video sr trained on REDS (6 frames), tested on REDS4
python -m torch.distributed.launch --nproc_per_node=8 --master_port=1234 main_train_vrt.py --opt options/vrt/001_train_vrt_videosr_bi_reds_6frames.json --dist True
# 002, video sr trained on REDS (16 frames), tested on REDS4
python -m torch.distributed.launch --nproc_per_node=8 --master_port=1234 main_train_vrt.py --opt options/vrt/002_train_vrt_videosr_bi_reds_16frames.json --dist True
# 003, video sr trained on Vimeo (bicubic), tested on Vid4 and Vimeo
python -m torch.distributed.launch --nproc_per_node=8 --master_port=1234 main_train_vrt.py --opt options/vrt/003_train_vrt_videosr_bi_vimeo_7frames.json --dist True
# 004, video sr trained on Vimeo (blur-downsampling), tested on Vid4, Vimeo and UDM10
python -m torch.distributed.launch --nproc_per_node=8 --master_port=1234 main_train_vrt.py --opt options/vrt/004_train_vrt_videosr_bd_vimeo_7frames.json --dist True
# 005, video deblurring trained and tested on DVD
python -m torch.distributed.launch --nproc_per_node=8 --master_port=1234 main_train_vrt.py --opt options/vrt/005_train_vrt_videodeblurring_dvd.json --dist True
# 006, video deblurring trained and tested on GoPro
python -m torch.distributed.launch --nproc_per_node=8 --master_port=1234 main_train_vrt.py --opt options/vrt/006_train_vrt_videodeblurring_gopro.json --dist True
# 007, video deblurring trained on REDS, tested on REDS4
python -m torch.distributed.launch --nproc_per_node=8 --master_port=1234 main_train_vrt.py --opt options/vrt/007_train_vrt_videodeblurring_reds.json --dist True
# 008, video denoising trained on DAVIS (noise level 0-50) and tested on Set8 and DAVIS
python -m torch.distributed.launch --nproc_per_node=8 --master_port=1234 main_train_vrt.py --opt options/vrt/008_train_vrt_videodenoising_davis.json --dist True
# 009, video frame interpolation trained on Vimeo (single frame interpolation), tested on Viemo, UCF101 and DAVIS-train
python -m torch.distributed.launch --nproc_per_node=8 --master_port=1234 main_train_vrt.py --opt options/vrt/009_train_vrt_videofi_vimeo_4frames.json --dist True
# 010, space-time video sr, using pretrained models from 003 and 009, tested on Vid4 and Viemo
# Not trained. Directly using 003 and 009.
Tip: The training process will terminate automatically at 20000 iteration due to a bug. Just resume training after that.
Bug
Bug: PyTorch DistributedDataParallel (DDP) does not support `torch.utils.checkpoint` well. To alleviate the problem, set `find_unused_parameters=False` when `use_checkpoint=True`. If there are other errors, make sure that unused parameters will not change during training loop and set `use_static_graph=True`.If you find a better solution, feel free to pull a request. Thank you.
Results
We achieved state-of-the-art performance on video SR, video deblurring and video denoising. Detailed results can be found in the paper.
Video Super-Resolution (click me)


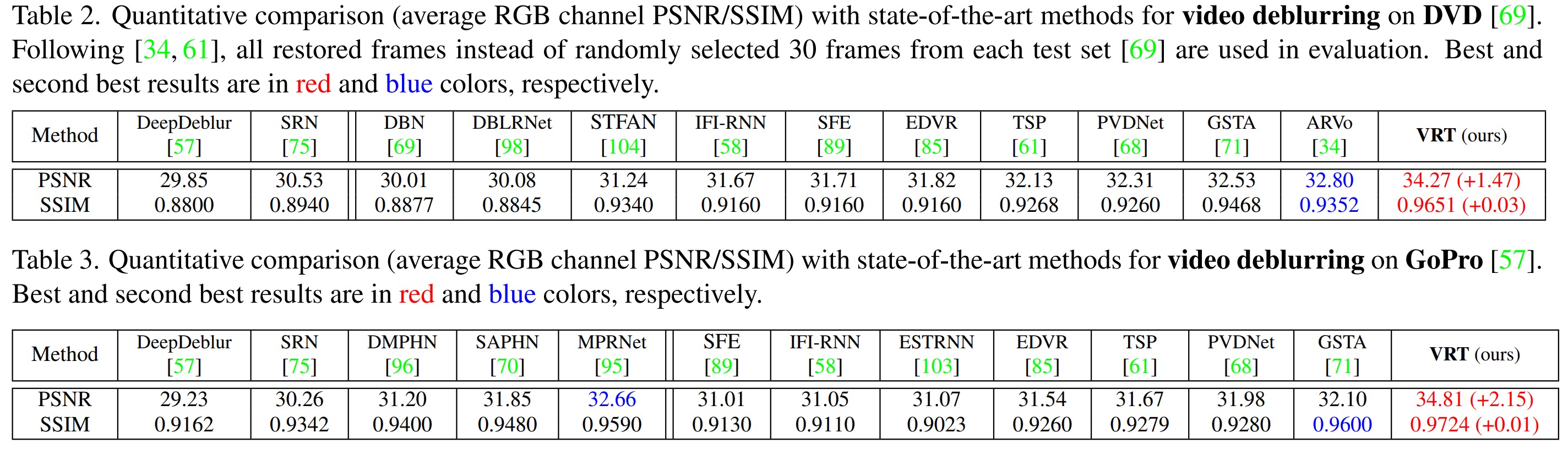
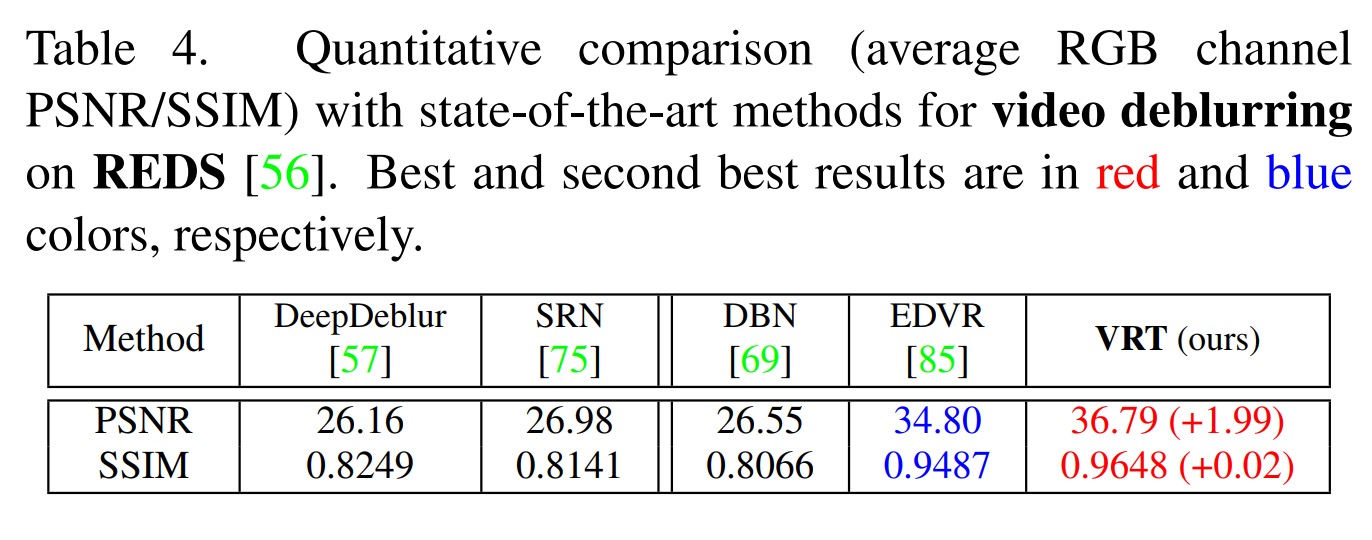
Video Deblurring

Video Denoising

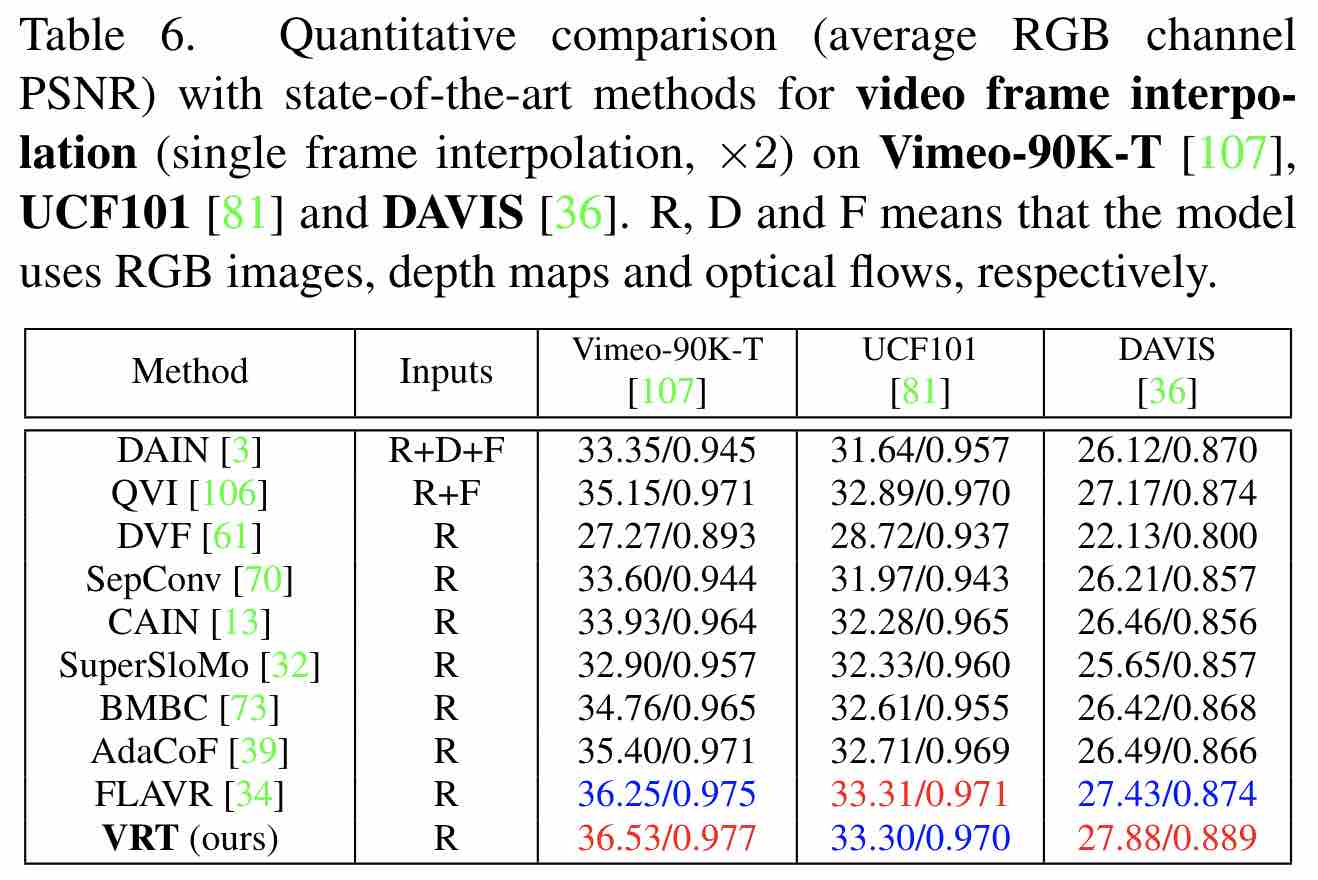
Video Frame Interpolation
Space-Time Video Super-Resolution

Citation
@article{liang2022vrt,
title={VRT: A Video Restoration Transformer},
author={Liang, Jingyun and Cao, Jiezhang and Fan, Yuchen and Zhang, Kai and Ranjan, Rakesh and Li, Yawei and Timofte, Radu and Van Gool, Luc},
journal={arXiv preprint arXiv:2201.12288},
year={2022}
}
License and Acknowledgement
This project is released under the CC-BY-NC license. We refer to codes from KAIR, BasicSR, Video Swin Transformer and mmediting. Thanks for their awesome works. The majority of VRT is licensed under CC-BY-NC, however portions of the project are available under separate license terms: KAIR is licensed under the MIT License, BasicSR, Video Swin Transformer and mmediting are licensed under the Apache 2.0 license.